::: tip
特に説明がない限り、文中のコンポーネントは関数コンポーネントを指します。
:::
基礎概念#
1. 関数型コンポーネントをどのように考えるべきか、クラスコンポーネントとの違いは何か?#
関数型コンポーネントとクラスコンポーネントは、全く異なるメンタルモデルです。
関数型コンポーネントは純粋な関数であり、単に props を受け取り、React 要素を返します。
クラスコンポーネントはクラスであり、独自の状態、ライフサイクル、およびインスタンスメソッドを持っています。
実践においては、関数型コンポーネントを純粋な関数と見なし、クラスコンポーネントをクラスと見なすべきです。ライフサイクルの考え方を忘れ、関数コンポーネント内でライフサイクルを模倣するためにさまざまな操作を行わないでください。
純粋な関数は副作用がなく、私たちのアプリケーションは意味を持つために副作用を持つ必要があります。したがって、React は副作用を処理するために useEffect を提供しています。
2. なぜコンポーネントが再レンダリングされるのか?#
これは React の特性であり、props または state が変化するたびにコンポーネントを再レンダリングします。これにより、コンポーネントの状態とビューが一致することが保証されます。
公式サイトの例を挙げてみましょう:
コンポーネントはシェフであり、React はウェイターです。

- レンダリングをトリガーする(ゲストの注文をキッチンに届ける)
- コンポーネントをレンダリングする(キッチンで注文を準備する)
- DOM にコミットする(テーブルに注文を置く)
props または state が変化すると、React は再レンダリングをトリガーし、関数を再実行します。
最終的なコミット段階では、React は関数の実行結果に基づいて可能な限り DOM ノードを再利用し、パフォーマンスを向上させます。
したがって、React において再レンダリングはバグではなく、特性です。パフォーマンスの問題を心配する必要はなく、React は自動的に最適化します。
公式ドキュメントと一緒にこの文章を読むことをお勧めします: Why React Re-Renders
疑問がある場合は、参考資料を何度か見直すことをお勧めします:
- Render and Commit
- Why React Re-Renders
- 定期的に読み返すことで新たな発見があります
3. State とは何か、なぜ必要なのか、なぜ時々その値が期待通りにならないのか?#
コンポーネントはユーザーの操作に応じて反応する必要があり、ユーザーの操作はコンポーネントの状態を変化させます。したがって、コンポーネントの状態を保存する場所が必要であり、それが state です。
state が変化すると、React はコンポーネントを再レンダリングします。 これが State の動作メカニズムです。
また、これは state の値が期待と一致しない理由でもあります。なぜなら、再レンダリングのたびに関数が実行され、そのたびに state は異なる値を持つからです。すべてのレンダリングにおいて、state は独立しており、互いに影響を与えません。
以下は例です:
const Counter = () => {
const [count, setCount] = useState(0)
const onClick = () => {
setInterval(() => {
setCount(count + 1)
}, 1000)
}
return (
<div>
<p>Count: {count}</p>
<button onClick={onClick}>Click me</button>
</div>
)
}
ボタンをクリックすると、1 秒ごとにカウンターの値が 1 増加します。しかし、カウンターの値は常に 1 のままであることに気づくでしょう。

タイマーは最初のレンダリング関数の実行時にのみ存在し、ここでの state は 0 です。したがって、タイマーが実行されるたびに取得される state は 0 であり、ページ上の値は常に 0 + 1 = 1 となります。
state を関数の状態のスナップショットとして理解することができ、各レンダリングごとに新しいスナップショットが作成され、これらのスナップショットは互いに影響を与えません。
4. useMemo とは何か、私はそれを使用する必要があるのか?#
useMemo は、関数の戻り値をキャッシュするために使用される Hook です。
したがって、唯一の目的はパフォーマンスを向上させることであり、再計算を避けることができます。
したがって、useMemo を取り除いてもコンポーネントの動作が変わらないことを確認する必要があります。
ただし、早すぎる最適化は悪の根源であることを明確に理解する必要があります。したがって、パフォーマンスの問題がない限り、useMemo を使用すべきではありません。
この文はやや曖昧ですが、適切なタイミングはいつでしょうか?
答えは、ほとんどの場合、useMemo を使用する必要はないということです。
公式ドキュメントによれば、次のコードを使用して計算の時間をテストできます:
console.time('filter array');
const visibleTodos = filterTodos(todos, tab);
console.timeEnd('filter array');
// filter array: 0.15ms
計算にかかる時間が 1ms を超える場合、useMemo を使用して計算結果をキャッシュすることを検討できます。
さらに:useMemo は最初のレンダリングのパフォーマンスを最適化することはできず、コンポーネントが更新されるときに再計算を避けるのに役立ちます。
useMemo がパフォーマンスを最適化できるのであれば、なぜどこでも使用しないのでしょうか?
理由は 3 つあります:
useMemo自体にはオーバーヘッドがあり、毎回のレンダリングで依存関係が変化したかどうかを比較するために実行されます。この計算のオーバーヘッドは、キャッシュする計算のオーバーヘッドよりも大きくなる可能性があります。(特に配列やオブジェクトなどの参照型の依存関係を考慮する必要があります)useMemoはコンポーネントの動作を予測不可能にし、バグを引き起こす可能性があります。useMemoはコンポーネントのコードを理解しにくくし、メンテナンスコストを増加させる可能性があります。
以前に述べたように、React は関数を繰り返し実行することでコンポーネントの更新を実現しますが、useMemo は特定の関数の実行をスキップするため、コンポーネントの動作が予測不可能になります。メンテナはこれらのスキップされた関数を理解する必要があり、メンテナンスコストが増加します。
5. useCallback とは何か、私はそれを使用する必要があるのか?#
useCallback は useMemo と同様の機能を持ち、計算結果をキャッシュするために使用されますが、使用シーンは異なります。
useCallback は関数をキャッシュするために使用され、useMemo は値をキャッシュするために使用されます。
関数または値が子コンポーネントに props として渡される場合、その関数または値が変化しなければ、子コンポーネントは再レンダリングされません。
したがって、多くの人が useCallback を使用して関数をキャッシュし、useMemo を使用して値をキャッシュします。
const TodoList = ({ todos, onClick }) => {
return (
<ul>
{/** ... */}
</ul>
)
}
const App = () => {
const todos = useMemo(() => filterTodos(todos, tab), [todos, tab])
const onClick = useCallback(() => {
// ...
}, [])
return (
<TodoList todos={todos} onClick={onClick} />
)
}
上記の例では、todos をキャッシュするために useMemo を使用し、onClick をキャッシュするために useCallback を使用しています。これにより、子コンポーネントの再レンダリングを回避できるため、パフォーマンスが向上したと考える人もいます。
しかし、実際にはこれはパフォーマンスを最適化していません。なぜなら、子コンポーネントがメモ化されたコンポーネントである場合にのみ、子コンポーネントの再レンダリングを回避できるからです。
const TodoList = React.memo(({ todos, onClick }) => {
return (
<ul>
{/** ... */}
</ul>
)
})
6. useEffect とは何か、それは何に使われるのか?#
useEffect は副作用を処理するために使用される Hook です。
デフォルトでは、コンポーネントがレンダリングされるたびに実行されますが、依存関係の配列を受け取ることができ、依存関係が変化したときのみ実行されます。
useEffect の設計目標は、関数コンポーネント内でライフサイクルの機能を提供することではなく、副作用を処理し、コンポーネントの状態を外部世界と同期させることです。
公式サイトの例を見てみましょう:
const ChatRoom = ({ roomId }) => {
useEffect(() => {
const connection = createConnection(roomId) // 接続を作成
connection.connect()
return () => {
connection.disconnect() // 接続を切断
}
}, [roomId])
}
// roomId のデフォルト値は 'general'
// 最初の操作で 'general' が 'travel' に変わる
// 2回目の操作で 'travel' が 'music' に変わる
コンポーネントの観点から見ると、その動作は次のようになります:
- コンポーネントが初めてレンダリングされると、useEffect がトリガーされ、'general' ルームに接続します。
- roomId が 'travel' に変わると、コンポーネントが再レンダリングされ、useEffect がトリガーされ、'general' ルームの接続を切断し、'travel' ルームに接続します。
- roomId が 'music' に変わると、コンポーネントが再レンダリングされ、useEffect がトリガーされ、'travel' ルームの接続を切断し、'music' ルームに接続します。
- コンポーネントがアンマウントされると、useEffect がトリガーされ、'music' ルームの接続を切断します。

完璧に見えますが、useEffect の観点から見ると、その動作は次のようになります:
- Effect は 'general' ルームに接続し、切断されるまで接続を維持します。
- Effect は 'travel' ルームに接続し、切断されるまで接続を維持します。
- Effect は 'music' ルームに接続し、切断されるまで接続を維持します。
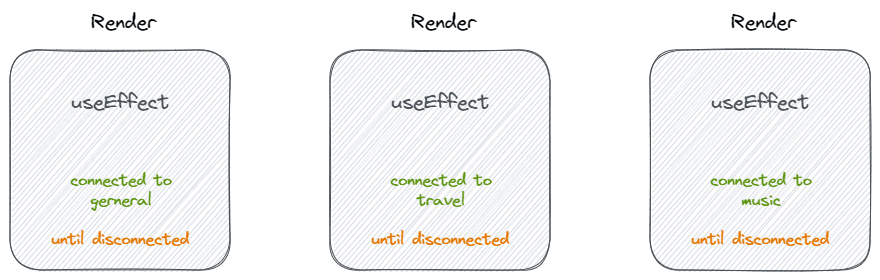
コンポーネントの観点から useEffect を考えると、useEffect はコンポーネントがレンダリングされた後またはアンマウントされる前に実行されるコールバック関数、ライフサイクルのようになります。
一方、useEffect の観点からは、外部世界との同期を開始または終了する方法にのみ関心があります。コンポーネントのレンダリングコードを書くのと同じように、state を受け取り、js を返します。レンダリングコードがマウント、更新、アンマウント時に何が起こるかは考慮しません。単一のレンダリングがどのようにあるべきかにのみ注目します。
最後に、次のような言葉があります:
問題は「この効果がいつ実行されるか」ではなく、「この効果がどの状態と同期するか」です。
useEffect (fn) // すべての状態
useEffect (fn, []) // 状態なし
useEffect (fn, [これらの状態])
重要なのは、useEffect がいつ実行されるかではなく、どの状態が同期されたかです。
状態管理#
1. 状態管理とは何か、なぜそれが React アプリケーションで重要なのか?#
状態管理とは、アプリケーション内でデータ(状態)を追跡、更新、維持するプロセスを指します。React アプリケーションにおいて、状態管理は特に重要であり、アプリケーションのユーザーインターフェースとインタラクションに直接影響を与えます。状態が変化すると、React は自動的に関連するコンポーネントを更新してこれらの変更を反映します。
React アプリケーションにおける状態管理の重要性は、主に以下の点にあります:
- 予測可能性:良好な状態管理はアプリケーションの動作をより予測可能にし、開発者は状態変化の出所を追跡しやすくなります。
- メンテナンス性:状態を整理し管理することで、コードがよりメンテナンスしやすくなり、アプリケーションの複雑性が低下します。これにより、チームはプロジェクト内でより効率的に協力できます。
- 拡張性:アプリケーションがますます複雑になると、状態管理は開発者がコードとロジックをより良く整理するのに役立ち、アプリケーションの拡張性を向上させます。
- パフォーマンスの最適化:状態を効果的に管理することで、不必要なコンポーネントの再レンダリングを減らし、アプリケーションのパフォーマンスを向上させることができます。
React では、コンポーネント内部の状態(useState Hook など)、コンテキスト(Context)API、サードパーティの状態管理ライブラリ(Redux、MobX、jotai など)を使用するなど、さまざまな状態管理方法があります。
2. 関数型コンポーネントで useState Hook を使用して状態を管理するにはどうすればよいか?#
useState は、React が提供する組み込みの Hook で、関数型コンポーネントに状態を追加および更新することを可能にします。
関数型コンポーネント内部で useState 関数を呼び出し、初期状態値を引数として渡します。useState は、現在の状態値と状態を更新するための関数を含む配列を返します。通常、配列の分割代入を使用してこれらの 2 つの値を取得します。
const [state, setState] = useState(initialState);
以下は簡単な例です:
import React, { useState } from 'react';
const Counter = () => {
// useState Hook を使用してカウンターの状態を初期化
const [count, setCount] = useState(0);
// カウンターの値を増加させる関数を定義
const increment = () => {
setCount(_count => _count + 1);
};
return (
<div>
<p>Current count: {count}</p>
<button onClick={increment}>Increment</button>
</div>
);
}
export default Counter;
この例では、シンプルなカウンターコンポーネントを作成しました。useState Hook を使用してカウンターの現在の値を保存し、カウンターを更新するための increment 関数を定義しました。ユーザーが "Increment" ボタンをクリックすると、カウンターの値が増加します。
useState は非常に便利な Hook ですが、使用中にいくつかのエラーが発生しやすい点があります。以下は注意が必要な問題です:
- 条件文内で useState を使用しない:React は Hook の呼び出し順序が一貫していることに依存して、状態と副作用を正しく関連付けて管理します。したがって、毎回同じ順序で Hook を呼び出すことを確認してください。ループ、条件文、またはネストされた関数内で Hook を呼び出さないでください。
// エラーの例
if (condition) {
const [state, setState] = useState(initialState);
}
- 非同期更新:
setState関数は非同期です。これは、setStateを呼び出すと、状態の更新が即座に反映されない可能性があることを意味します。現在の状態に基づいて新しい状態を計算する必要がある場合は、setState関数の関数形式を使用してください。
// 正しい例
const increment = () => {
setCount((prevCount) => prevCount + 1);
};
- 更新時に状態をマージする:クラスコンポーネントの
setStateとは異なり、関数型コンポーネントのuseStateは、状態を更新する際にオブジェクトを自動的にマージしません。状態がオブジェクトである場合は、更新時に手動で状態をマージすることを確認してください。
const [state, setState] = useState({ key1: 'value1', key2: 'value2' });
// エラーの例
setState({ key1: 'new-value1' }); // これにより key2 が失われます
// 正しい例
setState((prevState) => ({ ...prevState, key1: 'new-value1' }));
- 初期化時に重複計算を避ける:初期状態が複雑な計算や副作用関数を通じて取得される場合は、初期状態計算関数を
useStateに渡して、毎回のレンダリング時に計算を避けることができます。
const [state, setState] = useState(() => computeExpensiveInitialState());
- 初期値はコンポーネントが最初にレンダリングされるときにのみ使用される:その後の再レンダリングでは、設定された状態値が保持され、initialState が再適用されることはありません。
したがって、useState を使用する際には、この動作を正しく理解する必要があります。プロパティ(props)や他の外部変数に基づいて状態の初期値を設定する必要がある場合は、状態更新ロジックでこれらの依存関係を正しく処理することを確認してください。
最初のアプローチは、key 属性を使用してコンポーネントの再レンダリングをトリガーすることです。コンポーネントを使用する際に key 属性を一意の値に設定するだけです。プロパティ(initialCount など)に基づいてコンポーネントを再レンダリングする必要がある場合は、key をそのプロパティ値に設定できます:
import React, { useState } from 'react';
import MyComponent from './MyComponent';
function ParentComponent() {
const [initialCount, setInitialCount] = useState(0)
return <MyComponent key={initialCount} initialCount={initialCount} />;
}
export default ParentComponent;
この例では、initialCount プロパティが変化すると、MyComponent コンポーネントは新しい key 値を使用して再レンダリングされます。これにより、コンポーネントは新しい initialCount 値に基づいて初期化され、マウントされます。
2 番目のアプローチは、useEffect Hook を使用して外部変数の変化を処理し、必要に応じてコンポーネントの状態を更新することです。
import React, { useState, useEffect } from 'react';
function MyComponent({ initialCount }) {
const [count, setCount] = useState(initialCount);
useEffect(() => {
// initialCount プロパティ値が変化したときにコンポーネントの状態を更新
setCount(initialCount);
}, [initialCount]);
}
export default MyComponent;
key アプローチの利点は、メンタル負担が少なく、コンポーネントの状態がより明確で予測可能であることです。欠点は、key の変更がコンポーネント全体のアンマウントとマウントを引き起こすため、パフォーマンスオーバーヘッドが高くなる可能性があることです。
useEffect アプローチの利点は、プロパティ値が変化したときにのみ再レンダリングをトリガーし、コンポーネント全体をアンマウントおよびマウントする必要がないことです。パフォーマンスオーバーヘッドが低くなります。欠点は、発生する可能性のある副作用のクリーンアップと再適用を手動で管理する必要があり、プロパティ値の変化と状態更新を処理するためにより多くのコードが必要になることです。コンポーネントの状態がより複雑になります。
具体的なニーズとパフォーマンス要件に応じて、これら 2 つのアプローチの間でトレードオフを行うことができます。私個人としては、パフォーマンスは早急に考慮する問題ではなく、むしろコードのメンテナンス性や状態の予測可能性がプロジェクトの品質に与える影響が大きいと考えています。そのため、ほとんどのシナリオでは key アプローチを優先的に推奨します。
3. コンテキスト(Context)API とは何か、それは状態共有の問題をどのように解決するのか?#
コンテキスト(Context)API は、コンポーネントツリー内で状態を共有するための方法であり、明示的にプロパティ(props)を介して逐次渡す必要がありません。特定のレベルで値を設定し、より低いレベルの任意のコンポーネントでその値に直接アクセスできるようにします。これは、複数のレベルにまたがる共有状態を管理する際に非常に便利であり、プロパティを逐次渡す手間を省きます。
Context API を使用するには、次の手順を実行します:
- コンテキストオブジェクトを作成する:
React.createContext関数を使用して新しいコンテキストオブジェクトを作成します。この関数は、マッチするコンテキストプロバイダー(Provider)が見つからない場合に使用されるデフォルト値を引数として受け取ります。
const MyContext = React.createContext(defaultValue);
- コンテキストプロバイダー(Provider)を追加する:コンポーネントツリーの適切な位置にコンテキストプロバイダーを追加します。プロバイダーは、value 属性を受け取り、この属性がコンシューマー(Consumer)に渡されるコンテキスト値として使用されます。
<MyContext.Provider value={/* 共有値 */}>
{/* 子コンポーネント */}
</MyContext.Provider>
- 子コンポーネントでコンテキストを使用する:コンポーネントツリーの任意の低いレベルで、
useContextHook またはコンテキストコンシューマー(Consumer)コンポーネントを使用してコンテキスト値にアクセスできます。
// useContext Hook を使用
import React, { useContext } from 'react';
function MyComponent() {
const contextValue = useContext(MyContext);
// ...
}
// Context.Consumer コンポーネントを使用
import React from 'react';
function MyComponent() {
return (
<MyContext.Consumer>
{contextValue => {
// ...
}}
</MyContext.Consumer>
);
}
Context API を使用することで、コンポーネントツリーの任意の位置で状態を簡単に共有でき、逐次プロパティを渡す必要がなくなります。これにより、複数のレベルにまたがるコンポーネント間の状態共有がより簡潔かつ効率的になります。ただし、コンテキストを過度に使用すると、コンポーネント間の結合が強くなりすぎ、コードのメンテナンス性が低下する可能性があるため、Context API を使用する際には、確実にグローバル状態共有が必要なシナリオで使用するようにしてください。
4. jotai ライブラリとは何か、それはアプリケーションの状態管理にどのように役立つのか?#
Jotai は、React アプリケーション向けに設計された軽量の状態管理ライブラリです。原子(atoms)とセレクター(selectors)の概念に基づいており、状態管理をシンプルかつ効率的にします。Jotai の核心的な考え方は、状態を最小の、組み合わせ可能な単位(原子)に分解することで、状態の管理と追跡を容易にすることです。Redux や MobX などの他の状態管理ライブラリと比較して、Jotai はより軽量で学習が容易です。
Jotai を使用することの利点は、Context API を使用することと比較して、よりシンプルで柔軟でメンテナンスが容易であることです。以下はいくつかの理由です:
-
シンプルで使いやすい。
Jotai を使用するには、原子(atom)を作成し、React Hooks を使用するだけで状態管理ができます。Context API と比較して、Jotai のコードはよりシンプルで使いやすいです。 -
高い柔軟性。
Jotai は、異なる原子を自由に組み合わせて、より複雑な状態を作成できるため、状態管理がより柔軟で拡張可能になります。Context API と比較して、Jotai の柔軟性は高いです。 -
より良いパフォーマンス。
Jotai を使用すると、Context API でのプロバイダーとコンシューマーコンポーネントの使用によって引き起こされる無駄なレンダリングを回避でき、アプリケーションのパフォーマンスが向上します。Jotai はコンポーネントの再レンダリングを自動的に最適化し、原子状態が変化したときにのみ関連するコンポーネントを更新します。 -
メンテナンスが容易。
Jotai を使用することで、状態管理がより明確で、明示的で、メンテナンスが容易になります。状態を複数の原子に分解することで、各原子が単一の状態値を持ち、状態の変化をより良く制御し、アプリケーションの状態を維持できます。
Jotai を使用することで、状態管理がよりシンプルで柔軟で、メンテナンスが容易になり、パフォーマンスも向上します。もちろん、Context API を使用して状態管理を行うことも可能であり、よりネイティブですが、複雑な状態を処理する際には、より多くのコードを書く必要があり、パフォーマンスの問題を引き起こす可能性があります。したがって、状態管理ライブラリを選択する際には、具体的な状況に応じて選択する必要があります。
データの受け渡しと処理#
1. React コンポーネント間でデータ(props)を渡すにはどうすればよいか?#
- 親コンポーネントから子コンポーネントにデータを渡す
親コンポーネントで子コンポーネントを使用する際、子コンポーネントにプロパティを追加することでデータを渡すことができます。例えば:
function Parent() {
const data = {name: 'John', age: 30};
return <Child data={data} />;
}
function Child(props) {
return (
<div>
<p>Name: {props.data.name}</p>
<p>Age: {props.data.age}</p>
</div>
);
}
この例では、親コンポーネント Parent が子コンポーネント Child に data という名前のオブジェクトを渡しており、子コンポーネントは props.data を介してこのオブジェクトにアクセスできます。
- 子コンポーネントから親コンポーネントにデータを渡す
子コンポーネント内で、親コンポーネントから渡された関数を呼び出すことで、親コンポーネントにデータを渡すことができます。例えば:
function Parent() {
function handleChildData(data) {
console.log(data);
}
return <Child onData={handleChildData} />;
}
function Child(props) {
function handleClick() {
props.onData('Hello, parent!');
}
return <button onClick={handleClick}>Click me</button>;
}
この例では、子コンポーネント Child が props.onData 関数を呼び出すことで親コンポーネントにデータを渡しています。
- 兄弟コンポーネント間でデータを渡す
兄弟コンポーネント間でデータを渡すには、共通の親コンポーネント内で状態を定義し、その状態を props 属性として渡すことができます。例えば:
function Parent() {
const [data, setData] = useState('Hello, world!');
return (
<>
<Sibling1 data={data} />
<Sibling2 setData={setData} />
</>
);
}
function Sibling1(props) {
return <p>{props.data}</p>;
}
function Sibling2(props) {
function handleClick() {
props.setData('Hello, sibling 1!');
}
return <button onClick={handleClick}>Click me</button>;
}
この例では、Sibling1 と Sibling2 は兄弟コンポーネントであり、共通の親コンポーネント Parent 内の状態 data を介して通信しています。Sibling1 は props.data 属性を通じてデータを取得し、Sibling2 は props.setData 関数を通じてデータを更新します。
2. React における "lift state up"(状態の持ち上げ)パターンとは何か?なぜそれがデータの受け渡しと処理に重要なのか?#
"状態の持ち上げ"(lift state up)は、React における一般的なパターンであり、コンポーネント間のデータの受け渡しと状態管理を処理するために使用されます。このパターンの主な考え方は、コンポーネント間で共有される状態を共通の親コンポーネントに持ち上げて管理することで、コンポーネント間のデータの流れをより良く管理し調整することです。
状態を共通の親コンポーネントに持ち上げることで、状態を props として子コンポーネントに渡すことができ、コンポーネント間でデータを共有できます。これにより、コンポーネント間のデータの受け渡しがより明確で直感的になり、コンポーネント間の相互依存や相互に状態を変更する問題を回避できます。また、このパターンは、重複した状態管理コードを減らし、コードをより簡潔でメンテナンスしやすくします。
"状態の持ち上げ" パターンは、コンポーネント間のデータの受け渡しと状態管理を処理する上で非常に重要です。React において、コンポーネント間のデータの受け渡しは通常、props 属性を介して実現されます。コンポーネントが共有状態にアクセスする必要がある場合、これらの状態を共通の親コンポーネントに持ち上げて管理し、状態を props 属性として子コンポーネントに渡すことができます。このパターンにより、コンポーネント間のデータの受け渡しがより明確で直感的になり、コンポーネント間の相互依存や相互に状態を変更する問題を回避できます。
さらに、"状態の持ち上げ" パターンは、コードをより信頼性が高く、メンテナンスしやすくします。共通の親コンポーネントで状態を管理することで、重複した状態管理コードを減らし、状態ロジックを親コンポーネントにカプセル化することができ、コードがより簡潔でメンテナンスしやすくなります。
3. 非同期データのロードと更新(API からデータを取得するなど)をどのように処理するか?#
- useEffect Hook を使用する
useEffect Hook を使用して非同期データのロードと更新を処理できます。useEffect 内で非同期関数を使用してデータを取得し、useState Hook を使用してデータを保存し、状態を更新します。例えば:
import { useEffect, useState } from 'react';
function App() {
const [data, setData] = useState([]);
useEffect(() => {
async function fetchData() {
const response = await fetch('https://api.example.com/data');
const data = await response.json();
setData(data);
}
fetchData();
}, []);
return (
<ul>
{data.map((item) => (
<li key={item.id}>{item.title}</li>
))}
</ul>
);
}
この例では、useEffect Hook を使用して非同期でデータを取得し、useState Hook を使用してデータを保存し、状態を更新しています。useEffect の第二引数は空の配列であり、コンポーネントがマウントされるときにのみ実行されます。
- イベントコールバックを使用する
コンポーネント内でイベントコールバックを使用して非同期データのロードと更新を処理できます。例えば:
import { useState } from 'react';
function App() {
const [data, setData] = useState([]);
async function fetchData() {
const response = await fetch('https://api.example.com/data');
const data = await response.json();
setData(data);
}
return (
<div>
<button onClick={fetchData}>Load data</button>
<ul>
{data.map((item) => (
<li key={item.id}>{item.title}</li>
))}
</ul>
</div>
);
}
この例では、イベントコールバックを使用して非同期データのロードと更新を処理しています。ボタンをクリックすると、fetchData 関数が呼び出され、データを再取得し、状態に保存します。
どの方法を使用するかは具体的なニーズに依存します。Event と Effect を正しく区別することは非常に重要です。次の文書を参照してください:separating-events-from-effects
4. 制御されたコンポーネントと非制御コンポーネントとは何か?それぞれのデータ処理における適用シーンは何か?#
制御されたコンポーネントと非制御コンポーネントは、通常、フォーム要素(入力ボックス、選択ボックス、ラジオボタンなど)に関連する概念です。
ただし、実際にはこれらの概念は非フォーム要素のコンポーネントにも拡張できます。重要なのは、コンポーネント内部の状態をどのように管理し、外部からのデータをどのように処理するかです。以下は、非フォーム要素のコンポーネントに制御されたおよび非制御の概念を適用する方法を示す簡単な例です:
制御されたコンポーネント(非フォーム要素):
import React from 'react';
function ControlledDiv({ content, onContentChange }) {
const handleClick = () => {
onContentChange('New Content');
};
return <div onClick={handleClick}>{content}</div>;
}
この例では、ControlledDiv コンポーネントは content プロパティと onContentChange コールバック関数を受け取ります。ユーザーがこのコンポーネントをクリックすると、コールバック関数がトリガーされ、外部の content を更新します。これは、コンポーネント内部の状態が外部によって制御されていることを意味し、したがって制御されたコンポーネントと見なすことができます。
非制御コンポーネント(非フォーム要素):
import React, { useState } from 'react';
function UncontrolledDiv() {
const [content, setContent] = useState('Initial Content');
const handleClick = () => {
setContent('New Content');
};
return <div onClick={handleClick}>{content}</div>;
}
この例では、UncontrolledDiv コンポーネントは内部で content 状態を維持しています。ユーザーがこのコンポーネントをクリックすると、内部の状態が直接更新され、外部からデータを取得する必要はありません。したがって、このコンポーネントは非制御コンポーネントと見なされます。
要するに、制御されたコンポーネントと非制御コンポーネントの概念は主にフォーム要素に関連していますが、実際には非フォーム要素のコンポーネントにも拡張でき、重要なのはコンポーネントの状態の管理とデータ処理の方法です。
5. React の useCallback と useMemo Hooks を使用してデータ処理と関数の受け渡しを最適化するにはどうすればよいか?#
useCallback と useMemo は、React の 2 つの Hooks であり、データ処理と関数の受け渡しを最適化し、不必要なコンポーネントの再レンダリングを避けるのに役立ちます。以下は useMemo の例です:
import { useMemo, memo, useState } from "react";
const ChildComponent = memo(function ChildComponent({ data }) {
console.log("Childcomponent render");
return (
<div>
<p>Name: {data.name}</p>
<p>Age: {data.age}</p>
</div>
);
});
function ParentComponent() {
const [num, setNum] = useState(0);
// この例は学ばないでください。パフォーマンスの問題がない場合は useMemo useCallback を使用しないでください
const data = useMemo(() => {
return { name: "John", age: 30 };
}, []);
return (
<>
<div>
num: {num}{" "}
<button onClick={() => setNum((_num) => _num + 1)}>increase</button>
</div>
<ChildComponent data={data} />
</>
);
}
export default ParentComponent;
この例では、ParentComponent が useMemo でオブジェクトをラップし、それを props としてメモ化された ChildComponent に渡しています。ChildComponent はメモ化されているため、data が変化しない限り再レンダリングされません。
increase ボタンをクリックすると、ParentComponent が再レンダリングされますが、data は useMemo でラップされているため、data の参照は変わらず、ChildComponent は再レンダリングされません。
::: tip
ChildComponent は React.memo でラップされたコンポーネントである必要があります。上記の useMemo の最適化が機能するためです。
これは、ParentComponent が再レンダリングされると、その子コンポーネントも再レンダリングされるため、props が変化していなくても、子コンポーネントは再レンダリングされます。子コンポーネントが React.memo コンポーネントである場合にのみ、React は Object.is を使用して props の変化を比較し、再レンダリングをスキップするかどうかを決定します。
:::
6. React のカスタム Hooks を利用してデータ処理ロジックをカプセル化し再利用するにはどうすればよいか?#
カスタム Hooks は、関数コンポーネント内で状態や副作用のロジックをカプセル化し再利用するための方法です。カスタム Hooks の名前は通常、use で始まります。以下は、シンプルなカスタム Hook の例です:
import React, { useState, useEffect } from 'react';
// データ処理ロジックをカプセル化するカスタム Hook を定義
function useDataHandling(data) {
const [processedData, setProcessedData] = useState(null);
useEffect(() => {
// データ処理ロジックを定義
function processData(data) {
// ... データ処理の過程 ...
return processedData;
}
// データを処理し、状態を更新
setProcessedData(processData(data));
}, [data]);
// 処理されたデータを返す
return processedData;
}
// 関数コンポーネント内でカスタム Hook を使用
function MyComponent({ data }) {
const processedData = useDataHandling(data);
// ... 処理されたデータを使用 ...
}
カスタム Hook は、コードをよりモジュール化し、明確にするのに役立ちます。再利用されないコードであっても、ロジックをカスタム Hook に分割することには一定の利点があります:
- 関心の分離:カスタム Hook は、コンポーネント内の異なる関心事(状態管理、副作用処理、データ処理など)を異なる Hook に分離できます。これにより、コンポーネントのコードがより簡潔になり、理解しやすくなります。
- ロジックのデカップリング:特定のロジックをカスタム Hook にカプセル化することで、コンポーネント間の結合度を下げ、コンポーネントをより柔軟にします。これにより、要件が変化した場合、カスタム Hook を変更しても他のコンポーネントに影響を与えません。
- テストが容易:カスタム Hook は、コンポーネントから独立してテストできます。これにより、特定のロジックに対して単体テストを作成でき、他のコンポーネントの影響を心配する必要がありません。
- 可読性の向上:カスタム Hook を使用することで、コンポーネントのコードがより説明的になります。なぜなら、Hook の名前はその機能や役割を直接反映することが多いためです。これにより、コードの可読性とメンテナンス性が向上します。
したがって、実際の開発において、再利用されないコードであっても、ロジックをカスタム Hook に分割することを検討する価値があります。コードのリファクタリングを行う際には、ロジックを適切なカスタム Hook に分割して、コードの品質を向上させることを考慮してください。