::: tip
Unless otherwise specified, the components mentioned in the text refer to functional components.
:::
Basic Concepts#
1. How should we view functional components, and what is the difference between them and class components?#
Functional components and class components are completely different mental models.
Functional components are pure functions; they simply accept props and return a React element.
Class components are classes that have their own state, lifecycle, and instance methods.
In practice, we should view functional components as pure functions and class components as classes. Forget about the lifecycle thinking; do not try to simulate lifecycle methods in functional components with various operations.
A pure function has no side effects, while our applications must have side effects to be meaningful. Therefore, React provides useEffect to handle side effects.
2. Why do components re-render?#
This is a feature of React; it re-renders components whenever props or state change. This ensures that the component's state remains consistent with the view.
Let's take an example from the official website:
The component is the chef, and React is the waiter.

- Triggering a render (delivering the guest’s order to the kitchen)
- Rendering the component (preparing the order in the kitchen)
- Committing to the DOM (placing the order on the table)
When props or state change, React triggers a re-render, which means the function is executed again.
In the final Commit phase, React tries to reuse DOM nodes as much as possible based on the function's execution results to improve performance.
So in React, re-rendering is not a bug but a feature. There is no need to worry about performance issues; React will optimize automatically.
It is recommended to refer to the official documentation along with this article: Why React Re-Renders
If you still have questions, it is advisable to review the reference materials a few more times:
- Render and Commit
- Why React Re-Renders
- Reading it periodically will yield insights.
3. What is state, why do we need it, and why does its value sometimes not match expectations?#
Components need to respond to user actions, and user actions can cause changes in the component's state. Therefore, we need a place to store the component's state, which is state.
When state changes, React re-renders the component. This is the mechanism of State.
This is also why the value of state may not match expectations, because each re-render is a function execution, and in each function execution, state has different values. All these renders have independent states that do not affect each other.
Here is an example:
const Counter = () => {
const [count, setCount] = useState(0)
const onClick = () => {
setInterval(() => {
setCount(count + 1)
}, 1000)
}
return (
<div>
<p>Count: {count}</p>
<button onClick={onClick}>Click me</button>
</div>
)
}
After clicking the button, the counter value will increase by 1 every second. However, we will find that the counter value remains at 1.

We can see that the timer only runs during the first execution of the function, and the state here is 0, so every time the timer executes, it retrieves the state as 0, which means the displayed value will always be 0 + 1 = 1.
We can understand state as a snapshot of function state; each render has a new snapshot, and these snapshots do not affect each other.
4. What is useMemo, and do I need to use it?#
useMemo is a Hook that can be used to cache the return value of a function.
So its only purpose is to improve performance because it can avoid repeated calculations.
Therefore, we must ensure that even when useMemo is removed, the behavior of the component does not change.
However, we should be clear that premature optimization is the root of all evil, so we should not use useMemo when there are no performance issues.
This statement is somewhat vague; when is the appropriate time to use it?
The answer is that in the vast majority of cases, we do not need to use useMemo.
According to the official documentation, we can use the following code to test the time taken for a calculation:
console.time('filter array');
const visibleTodos = filterTodos(todos, tab);
console.timeEnd('filter array');
// filter array: 0.15ms
When our calculation takes longer than 1ms, we can consider using useMemo to cache the calculation result.
Additionally, useMemo does not optimize the performance of the first render; it only helps us avoid repeated calculations when the component updates.
Since useMemo can optimize performance, why not use it everywhere?
There are three reasons:
useMemoitself has overhead; it executes on every render to compare whether dependencies have changed, and this computational overhead may be greater than the computation we want to cache (especially considering reference types like arrays and objects).useMemocan make the behavior of components unpredictable, leading to bugs.useMemocan make the component's code harder to understand, increasing maintenance costs.
As mentioned earlier, React updates components by re-executing functions, while useMemo skips certain function executions, which can lead to unpredictable component behavior. Maintainers need to understand these skipped functions, which increases maintenance costs.
5. What is useCallback, and do I need to use it?#
useCallback and useMemo serve the same purpose; both are used to cache some computed results, but their usage scenarios are different.
useCallback is used to cache functions, while useMemo is used to cache values.
When a function or a value is passed as props to a child component, if that function or value does not change, the child component will not re-render.
So many people use useCallback to cache functions and useMemo to cache values.
const TodoList = ({ todos, onClick }) => {
return (
<ul>
{/** ... */}
</ul>
)
}
const App = () => {
const todos = useMemo(() => filterTodos(todos, tab), [todos, tab])
const onClick = useCallback(() => {
// ...
}, [])
return (
<TodoList todos={todos} onClick={onClick} />
)
}
In the example above, we can see that we used useMemo to cache todos and useCallback to cache onClick. Some people might think this optimizes performance because we avoid re-rendering the child component.
But in reality, this does not optimize performance because only when the child component is a memoized component will it avoid re-rendering.
const TodoList = React.memo(({ todos, onClick }) => {
return (
<ul>
{/** ... */}
</ul>
)
})
6. What is useEffect, and what is it used for?#
useEffect is a Hook that can be used to handle side effects.
By default, it executes after every render of the component, but it can accept a dependency array, and it will only execute when the dependencies change.
The design goal of useEffect is not to provide lifecycle-like functionality in functional components, but to handle side effects, which means synchronizing the component's state with the external world.
Let's look at an example from the official website:
const ChatRoom = ({ roomId }) => {
useEffect(() => {
const connection = createConnection(roomId) // Create connection
connection.connect()
return () => {
connection.disconnect() // Disconnect
}
}, [roomId])
}
// Default roomId is 'general'
// First operation changes 'general' to 'travel'
// Second operation changes 'travel' to 'music'
From the component's perspective, its behavior is as follows:
- When the component first renders,
useEffectis triggered, connecting to the 'general' room. - When
roomIdchanges to 'travel', the component re-renders, triggeringuseEffect, disconnecting from the 'general' room and connecting to the 'travel' room. - When
roomIdchanges to 'music', the component re-renders, triggeringuseEffect, disconnecting from the 'travel' room and connecting to the 'music' room. - When the component unmounts,
useEffectis triggered, disconnecting from the 'music' room.

It looks perfect, but if we look at it from the perspective of useEffect, its behavior is as follows:
- The effect connects to the 'general' room until it disconnects.
- The effect connects to the 'travel' room until it disconnects.
- The effect connects to the 'music' room until it disconnects.
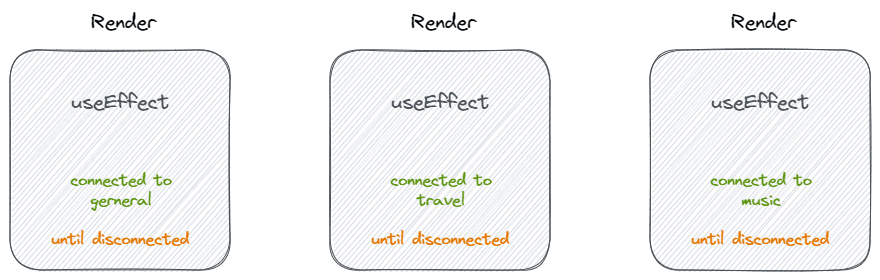
When we view useEffect from the perspective of the component, useEffect becomes a callback function, lifecycle that executes after the component has rendered or before it unmounts.
From the perspective of useEffect, we only care about how the application starts or stops synchronizing with the external world. Just like writing rendering code for components, we receive state and return JS. We do not consider what happens during mount, update, or unmount. We only focus on what a single render should look like.
Finally, let's look at this statement:
The question is not "when does this effect run" the question is "with which state does this effect synchronize with"
useEffect(fn) // all state
useEffect(fn, []) // no state
useEffect(fn, [these, states])
What matters is not when useEffect executes, but which states it synchronizes with.
State Management#
1. What is state management, and why is it important in React applications?#
State management refers to the process of tracking, updating, and maintaining data (state) within an application. In React applications, state management is particularly important because it directly affects the user interface and interactions of the application. When the state changes, React automatically updates the relevant components to reflect these changes.
The importance of state management in React applications is mainly reflected in the following aspects:
- Predictability: Good state management can make the behavior of the application more predictable, allowing developers to more easily trace and understand the sources of state changes.
- Maintainability: By organizing and managing state, code can be made easier to maintain, reducing the complexity of the application. This helps teams collaborate more efficiently on projects.
- Scalability: As applications become more complex, state management can help developers better organize code and logic, improving the scalability of the application.
- Performance Optimization: Effectively managing state can reduce unnecessary component re-renders, thereby improving application performance.
In React, there are various state management methods, such as using component internal state (like the useState Hook), the Context API, and third-party state management libraries (like Redux, MobX, or jotai).
2. How to use the useState Hook to manage state in functional components?#
useState is a built-in Hook provided by React that allows you to add and update state in functional components.
Inside a functional component, call the useState function and pass the initial state value as an argument. useState returns an array containing two elements: the current state value and a function to update the state. Typically, we use array destructuring to obtain these two values.
const [state, setState] = useState(initialState);
Here is a simple example:
import React, { useState } from 'react';
const Counter = () => {
// Initialize the counter state using useState Hook
const [count, setCount] = useState(0);
// Define a function to increase the counter value
const increment = () => {
setCount(_count => _count + 1);
};
return (
<div>
<p>Current count: {count}</p>
<button onClick={increment}>Increment</button>
</div>
);
}
export default Counter;
In this example, we created a simple counter component. We use the useState Hook to store the current value of the counter and define an increment function to update the counter. When the user clicks the "Increment" button, the counter value will increase.
useState is a very useful Hook, but there may be some common pitfalls during its use. Here are some issues to be aware of:
- Do not use useState in conditional statements: React relies on the consistent order of Hook calls to ensure proper association and management of state and side effects, so make sure to call Hooks in the same order on every render. Do not call Hooks inside loops, conditional statements, or nested functions.
// Incorrect example
if (condition) {
const [state, setState] = useState(initialState);
}
- Asynchronous updates: The
setStatefunction is asynchronous. This means that when you callsetState, the state update may not take effect immediately. If you need to calculate the new state based on the current state, use the functional update form ofsetState.
// Correct example
const increment = () => {
setCount((prevCount) => prevCount + 1);
};
- Merging state during updates: Unlike
setStatein class components,useStatein functional components does not automatically merge objects when updating state. If your state is an object, make sure to manually merge the state during updates.
const [state, setState] = useState({ key1: 'value1', key2: 'value2' });
// Incorrect example
setState({ key1: 'new-value1' }); // This will cause key2 to be lost
// Correct example
setState((prevState) => ({ ...prevState, key1: 'new-value1' }));
- Avoid repeated calculations during initialization: If your initial state needs to be obtained through complex calculations or side effect functions, you can pass an initial state calculation function to
useStateto avoid performing the calculation on every render.
const [state, setState] = useState(() => computeExpensiveInitialState());
- Initial value is only used during the first render: Subsequent re-renders will retain and use the already set state value, rather than reapplying
initialState.
Therefore, when using useState, it is important to understand this behavior correctly. If you need to set the initial value of the state based on props or other external variables, make sure to handle these dependencies correctly in the state update logic.
The first approach is to use the key property to trigger a re-render of the component, simply set the key property to a unique value when using the component. When you need to re-render the component based on a prop (like initialCount), you can set the key to that prop value:
import React from 'react';
import MyComponent from './MyComponent';
function ParentComponent() {
const [initialCount, setInitialCount] = useState(0)
return <MyComponent key={initialCount} initialCount={initialCount} />;
}
export default ParentComponent;
In this example, when the initialCount prop changes, the MyComponent component will re-render using the new key value. This will cause the component to initialize and mount based on the new initialCount value.
The second approach is to use the useEffect Hook to handle changes in external variables, thereby updating the component state as needed.
import React, { useState, useEffect } from 'react';
function MyComponent({ initialCount }) {
const [count, setCount] = useState(initialCount);
useEffect(() => {
// Update component state when initialCount prop value changes
setCount(initialCount);
}, [initialCount]);
}
export default MyComponent;
The advantage of the key approach is that it has a lower cognitive load, and the component's state is clearer and more predictable. The downside is that changing the key will cause the entire component to unmount and mount again, which may incur a higher performance cost.
The advantage of the useEffect approach is that it only triggers a re-render when the prop value changes, without needing to unmount and mount the entire component. The performance overhead is lower. The downside is that it requires manual management of potential side effects for cleanup and reapplication, requiring more code to handle prop value changes and state updates, making the component's state more complex.
Depending on specific needs and performance requirements, a trade-off can be made between these two approaches. Personally, I believe that performance should not be considered prematurely; rather, the maintainability of the code and the predictability of state may have a greater impact on project quality. Therefore, in most scenarios, I would prioritize recommending the key approach.
3. What is the Context API, and how does it solve the problem of state sharing?#
The Context API is a method in React for sharing state throughout the component tree without explicitly passing props down through every level. It allows you to set a value at a certain level of the component tree and then access that value directly in any component lower in the tree. This is very useful for managing shared state that spans multiple levels, avoiding the hassle of passing props down through many layers.
To use the Context API, you need to follow these steps:
- Create a context object: Use the
React.createContextfunction to create a new context object. This function accepts a default value as a parameter, which will be used when no matching context provider is found.
const MyContext = React.createContext(defaultValue);
- Add a context provider: Add a context provider at the appropriate place in the component tree. The provider accepts a value prop, which will be passed to consumers.
<MyContext.Provider value={/* shared value */}>
{/* children components */}
</MyContext.Provider>
- Use context in child components: In any lower-level component in the tree, you can use the
useContextHook or the context consumer component to access the context value.
// Using useContext Hook
import React, { useContext } from 'react';
function MyComponent() {
const contextValue = useContext(MyContext);
// ...
}
// Using Context.Consumer component
import React from 'react';
function MyComponent() {
return (
<MyContext.Consumer>
{contextValue => {
// ...
}}
</MyContext.Consumer>
);
}
By using the Context API, you can easily share state at any point in the component tree without having to pass props down through every level. This makes state sharing between components that span multiple levels more concise and efficient. However, it is important to note that overusing context can lead to tight coupling between components, which can reduce code maintainability. Therefore, when using the Context API, ensure that it is used in scenarios where global state sharing is genuinely needed.
4. What is the jotai library, and how does it help manage application state?#
Jotai is a lightweight state management library designed for React applications. It is based on the concepts of atoms and selectors, making state management simple and efficient. The core idea of Jotai is to break down state into the smallest, composable units (atoms), making it easier to manage and track state. Compared to other state management libraries like Redux or MobX, Jotai is lighter and easier to learn.
Using Jotai has advantages over using the Context API in terms of simplicity, flexibility, and maintainability. Here are some reasons:
-
Simple and easy to use.
Using Jotai only requires creating atoms and using React Hooks for state management. The code for using Jotai is simpler and easier to use compared to the Context API. -
Highly flexible.
Jotai allows you to freely combine and compose different atoms to create more complex states, making state management more flexible and scalable. The flexibility of using Jotai is higher than that of the Context API. -
Better performance.
Using Jotai can avoid unnecessary renders caused by using Provider and Consumer components in the Context API, thus improving application performance. Jotai automatically optimizes component re-renders and only updates related components when atom states change. -
Easier to maintain.
Using Jotai can make state management clearer, more explicit, and easier to maintain. By breaking down state into multiple atoms, each atom containing a single state value, you can better control state changes and maintain application state.
Using Jotai can make state management simpler, more flexible, easier to maintain, and perform better. Of course, the Context API can also be used for state management and is more native, but handling complex states may require more code and can easily lead to performance issues. Therefore, when choosing a state management library, it is essential to consider the specific situation.
Data Transmission and Processing#
1. How to pass data (props) between React components?#
- Passing data from parent component to child component
When using a child component in a parent component, you can pass data by adding props to the child component. For example:
function Parent() {
const data = {name: 'John', age: 30};
return <Child data={data} />;
}
function Child(props) {
return (
<div>
<p>Name: {props.data.name}</p>
<p>Age: {props.data.age}</p>
</div>
);
}
In this example, the parent component Parent passes an object named data to the child component Child, which can access this object via props.data.
- Passing data from child component to parent component
In the child component, you can pass data to the parent component by calling a function passed from the parent component. For example:
function Parent() {
function handleChildData(data) {
console.log(data);
}
return <Child onData={handleChildData} />;
}
function Child(props) {
function handleClick() {
props.onData('Hello, parent!');
}
return <button onClick={handleClick}>Click me</button>;
}
In this example, the child component Child passes data to the parent component by calling the props.onData function.
- Passing data between sibling components
To pass data between sibling components, you can define state in their common parent component and then pass that state as props to them. For example:
function Parent() {
const [data, setData] = useState('Hello, world!');
return (
<>
<Sibling1 data={data} />
<Sibling2 setData={setData} />
</>
);
}
function Sibling1(props) {
return <p>{props.data}</p>;
}
function Sibling2(props) {
function handleClick() {
props.setData('Hello, sibling 1!');
}
return <button onClick={handleClick}>Click me</button>;
}
In this example, Sibling1 and Sibling2 are sibling components that communicate through the state data in their common parent component Parent. Sibling1 retrieves the data via props.data, while Sibling2 updates the data using props.setData.
2. What is the "lift state up" pattern in React, and why is it important for data transmission and processing?#
"Lifting state up" is a common pattern in React used for handling data transmission and state management between components. The main idea of this pattern is to lift the shared state between components up to their common parent component for management, allowing for better management and coordination of data flow between components.
By lifting state to a common parent component, you can pass the state as props to child components, thus sharing data between them. This can make data transmission between components clearer and more intuitive, avoiding issues of components depending on each other and modifying each other's state. Additionally, this pattern can reduce duplicate state management code, making the code cleaner and easier to maintain.
The "lift state up" pattern is very important for handling data transmission and state management between components in React. In React, data transmission between components is typically achieved through props. When components need to access shared state, these states can be lifted to their common parent component for management, and the state can be passed as props to child components. This pattern can make data transmission between components clearer and more intuitive, avoiding issues of components depending on each other and modifying each other's state.
Moreover, the "lift state up" pattern can also make the code more reliable and maintainable. By managing state in a common parent component, you can reduce duplicate state management code and encapsulate state logic within the parent component, making the code cleaner and easier to maintain.
3. How to handle asynchronous data loading and updates (e.g., fetching data from an API)?#
- Using the useEffect Hook
You can use theuseEffectHook to handle asynchronous data loading and updates. InsideuseEffect, you can use an asynchronous function to fetch data and use theuseStateHook to store the data and update the state. For example:
import { useEffect, useState } from 'react';
function App() {
const [data, setData] = useState([]);
useEffect(() => {
async function fetchData() {
const response = await fetch('https://api.example.com/data');
const data = await response.json();
setData(data);
}
fetchData();
}, []);
return (
<ul>
{data.map((item) => (
<li key={item.id}>{item.title}</li>
))}
</ul>
);
}
In this example, we use the useEffect Hook to asynchronously fetch data and use the useState Hook to store and update the data. The second parameter of useEffect is an empty array, indicating that it should only execute once when the component mounts.
- Using event callbacks
You can handle asynchronous data loading and updates using event callbacks within the component. For example:
import { useState } from 'react';
function App() {
const [data, setData] = useState([]);
async function fetchData() {
const response = await fetch('https://api.example.com/data');
const data = await response.json();
setData(data);
}
return (
<div>
<button onClick={fetchData}>Load data</button>
<ul>
{data.map((item) => (
<li key={item.id}>{item.title}</li>
))}
</ul>
</div>
);
}
In this example, we use an event callback to handle asynchronous data loading and updates. When the button is clicked, the fetchData function is called to fetch data again and store it in the state.
Which method to use depends on the specific needs of the scenario. Correctly distinguishing between Event and Effect is very important; you can refer to this document: separating-events-from-effects
4. What are controlled components and uncontrolled components? What are their application scenarios in data processing?#
Controlled components and uncontrolled components are concepts typically used for form elements (like input fields, select boxes, and radio buttons).
However, these concepts can also be extended to non-form element components. The key lies in how the internal state of the component is managed and how external data is processed. Here is a simple example illustrating how to apply the concepts of controlled and uncontrolled components to non-form elements:
Controlled Component (non-form element):
import React from 'react';
function ControlledDiv({ content, onContentChange }) {
const handleClick = () => {
onContentChange('New Content');
};
return <div onClick={handleClick}>{content}</div>;
}
In this example, the ControlledDiv component receives a content prop and an onContentChange callback function. When the user clicks this component, it triggers the callback function to update the externally passed content. This means the internal state of the component is controlled by external factors, so it can be considered a controlled component.
Uncontrolled Component (non-form element):
import React, { useState } from 'react';
function UncontrolledDiv() {
const [content, setContent] = useState('Initial Content');
const handleClick = () => {
setContent('New Content');
};
return <div onClick={handleClick}>{content}</div>;
}
In this example, the UncontrolledDiv component maintains an internal content state. When the user clicks this component, it directly updates the internal state without needing to fetch data from external sources. Therefore, this component can be considered an uncontrolled component.
In summary, although the concepts of controlled and uncontrolled components primarily apply to form elements, they can actually be extended to non-form elements as well, with the key being how the component's state is managed and how data is processed.
5. How to use React's useCallback and useMemo Hooks to optimize data processing and function passing?#
useCallback and useMemo are two Hooks in React that can help optimize data processing and function passing, avoiding unnecessary component re-renders. Here is an example using useMemo:
import { useMemo, memo, useState } from "react";
const ChildComponent = memo(function ChildComponent({ data }) {
console.log("Child component render");
return (
<div>
<p>Name: {data.name}</p>
<p>Age: {data.age}</p>
</div>
);
});
function ParentComponent() {
const [num, setNum] = useState(0);
// Do not learn this example; do not use useMemo without performance issues
const data = useMemo(() => {
return { name: "John", age: 30 };
}, []);
return (
<>
<div>
num: {num}{" "}
<button onClick={() => setNum((_num) => _num + 1)}>increase</button>
</div>
<ChildComponent data={data} />
</>
);
}
export default ParentComponent;
In this example, ParentComponent uses useMemo to wrap an object and passes it as props to the memo-wrapped ChildComponent. Since ChildComponent is memo-wrapped, it will only re-render when data changes.
When we click the increase button, although ParentComponent re-renders, the reference of data remains unchanged due to useMemo, so ChildComponent will not re-render.
::: tip
Please note that ChildComponent must be a React.memo wrapped component for the optimization of useMemo to take effect.
This is because when ParentComponent re-renders, its child component will also re-render, regardless of whether its props have changed. Only when its child component is a React.memo component will React use Object.is to compare props for changes to decide whether to skip the re-render.
:::
6. How to leverage React's custom Hooks to encapsulate and reuse data processing logic?#
Custom Hooks are a way to encapsulate and reuse state and side effect logic in functional components. The naming of custom Hooks typically starts with "use." Here is a simple example of a custom Hook:
import React, { useState, useEffect } from 'react';
// Define a custom Hook for encapsulating data processing logic
function useDataHandling(data) {
const [processedData, setProcessedData] = useState(null);
useEffect(() => {
// Define data processing logic
function processData(data) {
// ... data processing steps ...
return processedData;
}
// Process data and update state
setProcessedData(processData(data));
}, [data]);
// Return processed data
return processedData;
}
// Use the custom Hook in a functional component
function MyComponent({ data }) {
const processedData = useDataHandling(data);
// ... use the processed data ...
}
Custom Hooks can help make code more modular and clear. Even without considering code reuse, splitting logic into custom Hooks still has certain advantages:
- Separation of concerns: Custom Hooks can separate different concerns (like state management, side effect handling, data processing, etc.) into different Hooks. This helps make component code cleaner and easier to understand and maintain.
- Decoupling logic: Encapsulating specific logic into a custom Hook can reduce the coupling between components, making them more flexible. This way, when requirements change, modifying the custom Hook will not affect other components.
- Easier testing: Custom Hooks can be tested independently of components. This means you can write unit tests for specific logic without worrying about the influence of other components.
- Better readability: Using custom Hooks can make component code more descriptive, as the names of Hooks often reflect their functionality and purpose. This helps improve code readability and maintainability.
Therefore, in actual development, even if a piece of code will not be reused, it is beneficial to split it into a custom Hook. When refactoring code, consider splitting logic into appropriate custom Hooks to improve code quality.